Fornax: Generating 4.8 million frames
Written onFornax is a collection of tools to visualize Path Finding Algorithms, it's written in Raku, uses Cairo to generate the frames.
The idea is that a program will solve the puzzle and generate the output
in Fornax Format, defined on project homepage.
And Fornax (the Raku program) will parse that output to generate a frame for
every iteration which can then be turned into a video with ffmpeg.
I'm writing this for my Bachelors project (Computer Graphics). We started with randomized DFS and crafted a maze that'll take it very long to solve if it enters the wrong path.
This is the maze:

The "wrong path" here is when it enters the free space on bottom left,
here is the "wrong path":
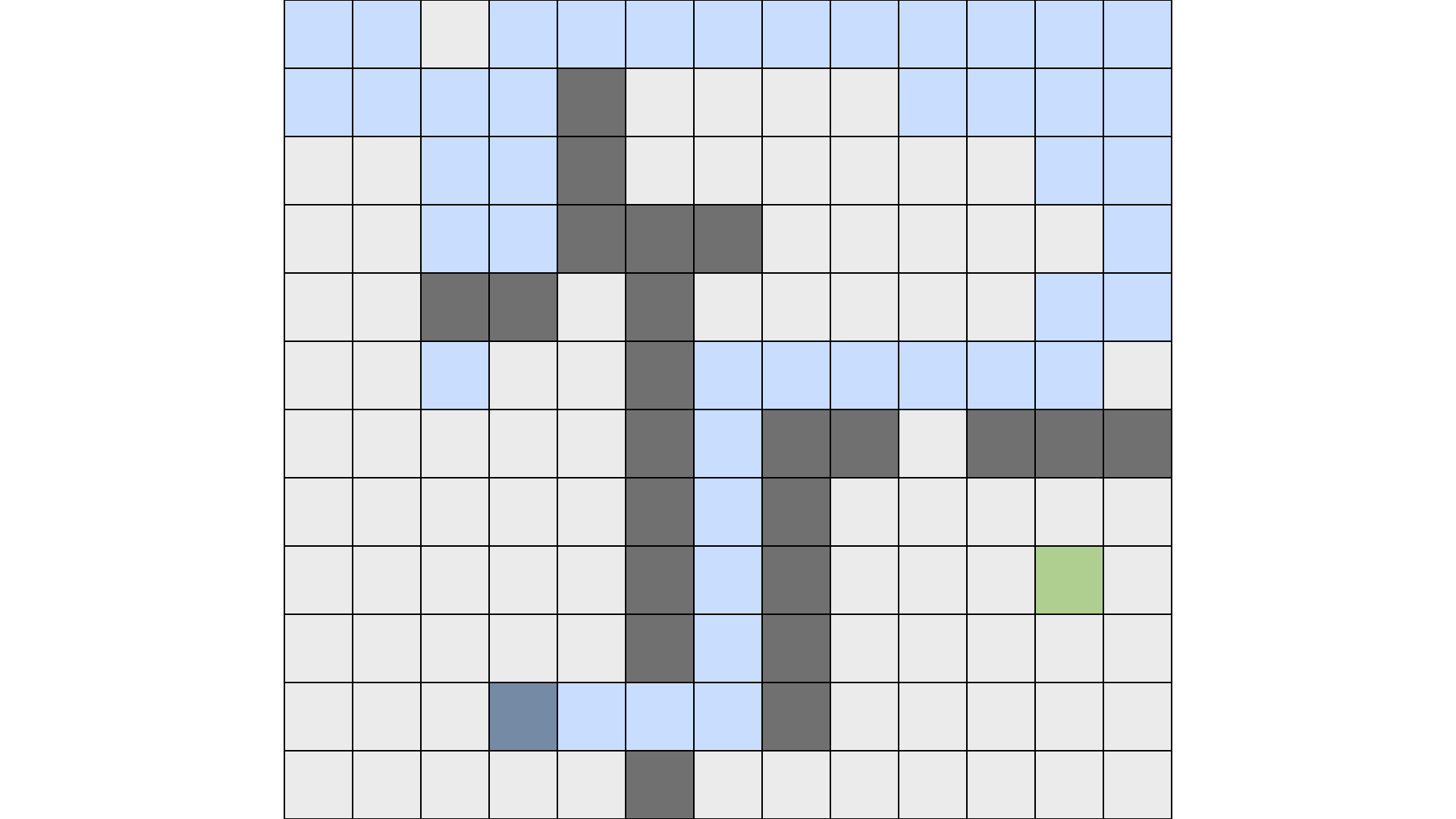
- Note: The blue square on (5, 2) indicates that it has been visited already, that is because I marked it as visited by mistake.
55 frames in & it took the "wrong path", now because it is DFS, it'll explore the whole depth before exiting the space. I don't have the numbers but it's going to take a lot of time to finish exploring that space.
I let the program run for some time, it's written in Java & is
single-threaded. I killed it after it had gone through ~4,875,913
iterations, that is around 4.8 million iterations, the solution file was
732M and 14M (compressed with xz -9).
I think the format could be improved, currently we're storing every grid of every iteration, instead we could only capture the changes.
So with the iterations, I ran fornax with this solution and set
batch size to 8 (it generates 8 images in parallel before moving on to next
batch). I went with this instead of using map with race/hyper because
for some reason that didn't make it any faster, I don't think it was
executing in parallel, didn't have time to document it.
I ran this on a machine with:
- 24GiB Memory
- 2GHz CPU (4) (
dmidecode -t processor) - aarch64 Architecture
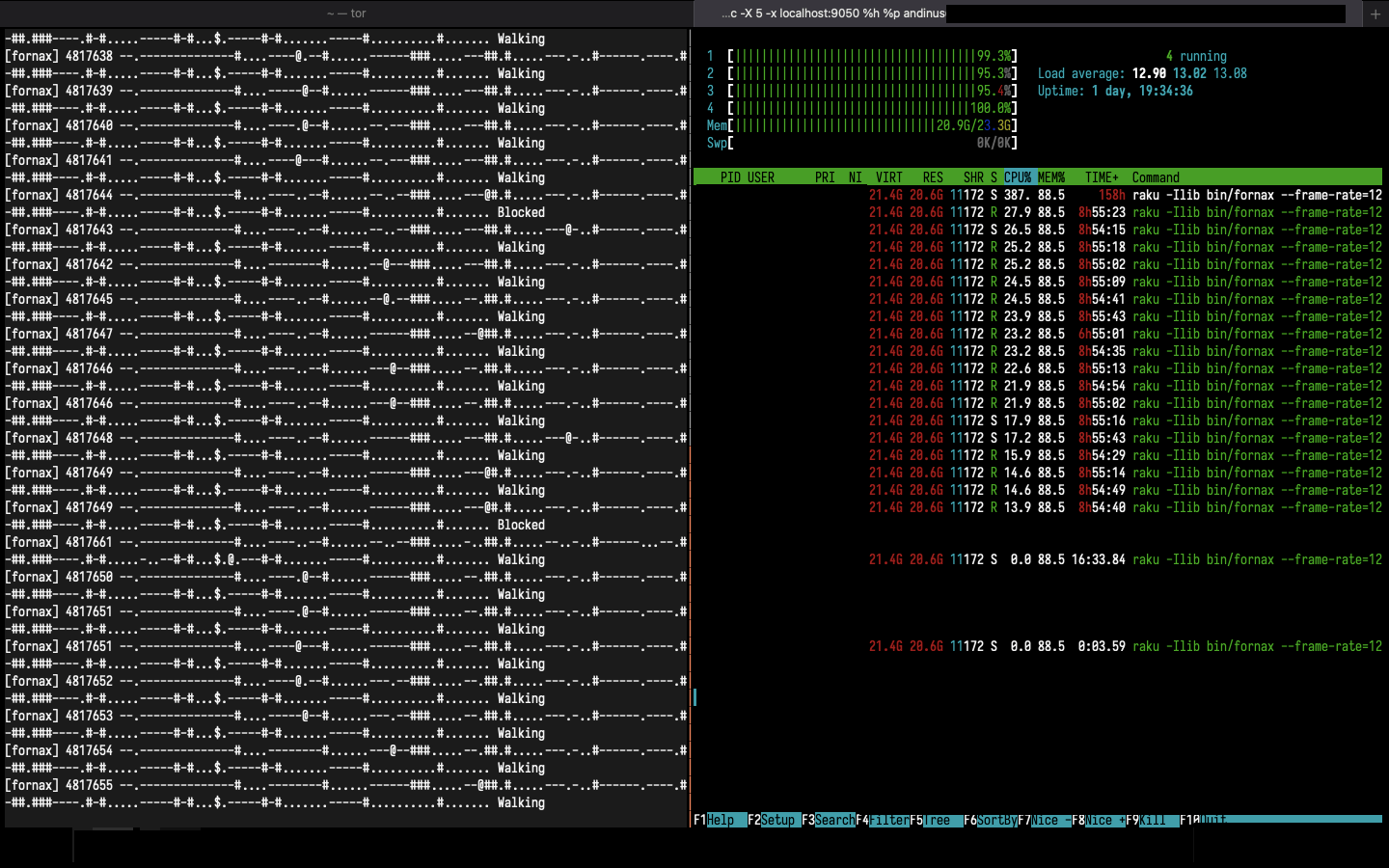
I took 3 screenshots while the program was runnning. The last one was at
4,817,655 iteration, the program was taking around 20.6GiB of memory.
Here is the screenshot (2021-11-07 08:52):
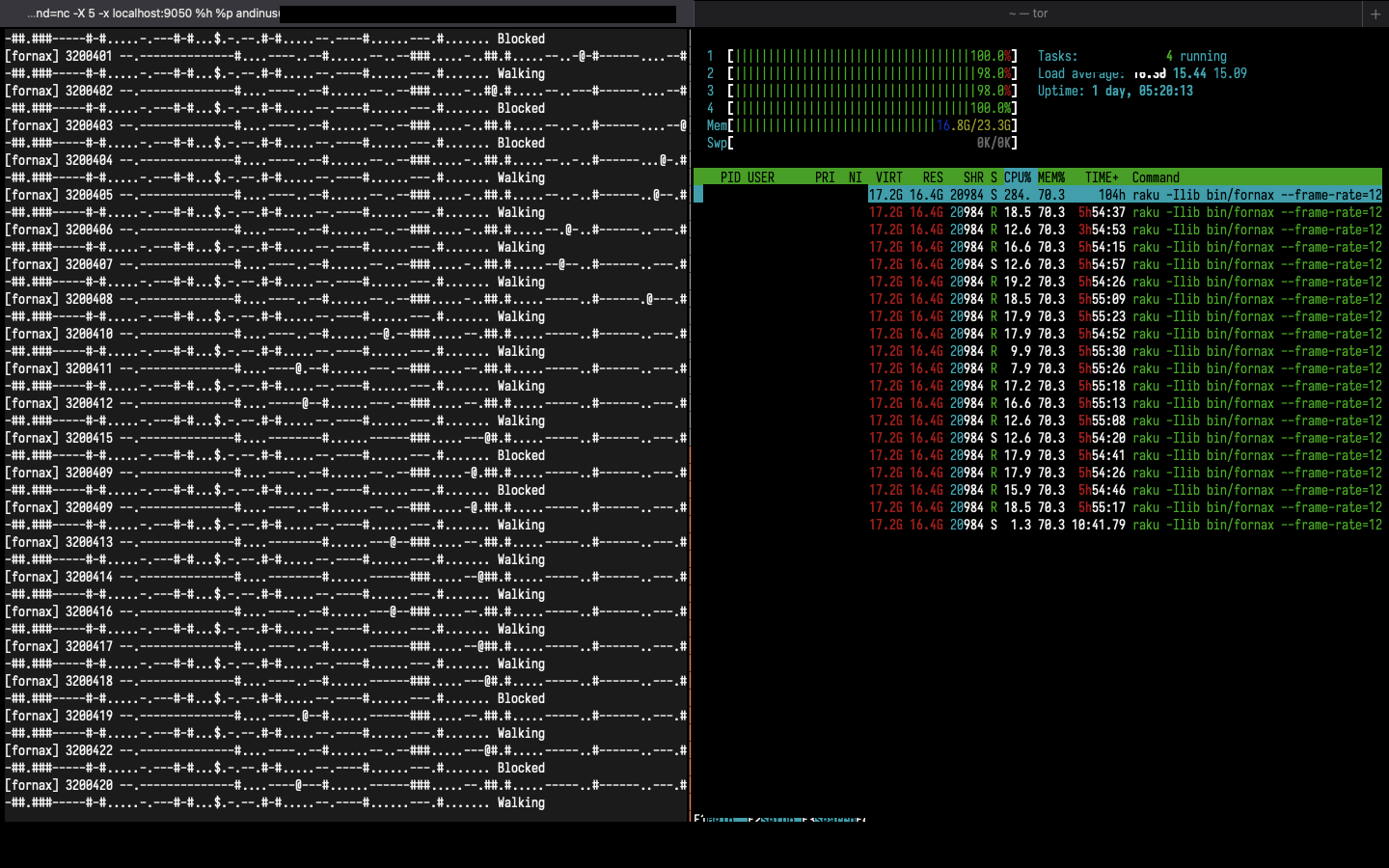
2021-11-06 18:38 (3,200,420 iteration):
2021-11-06 10:11 (2,237,422 iteration):
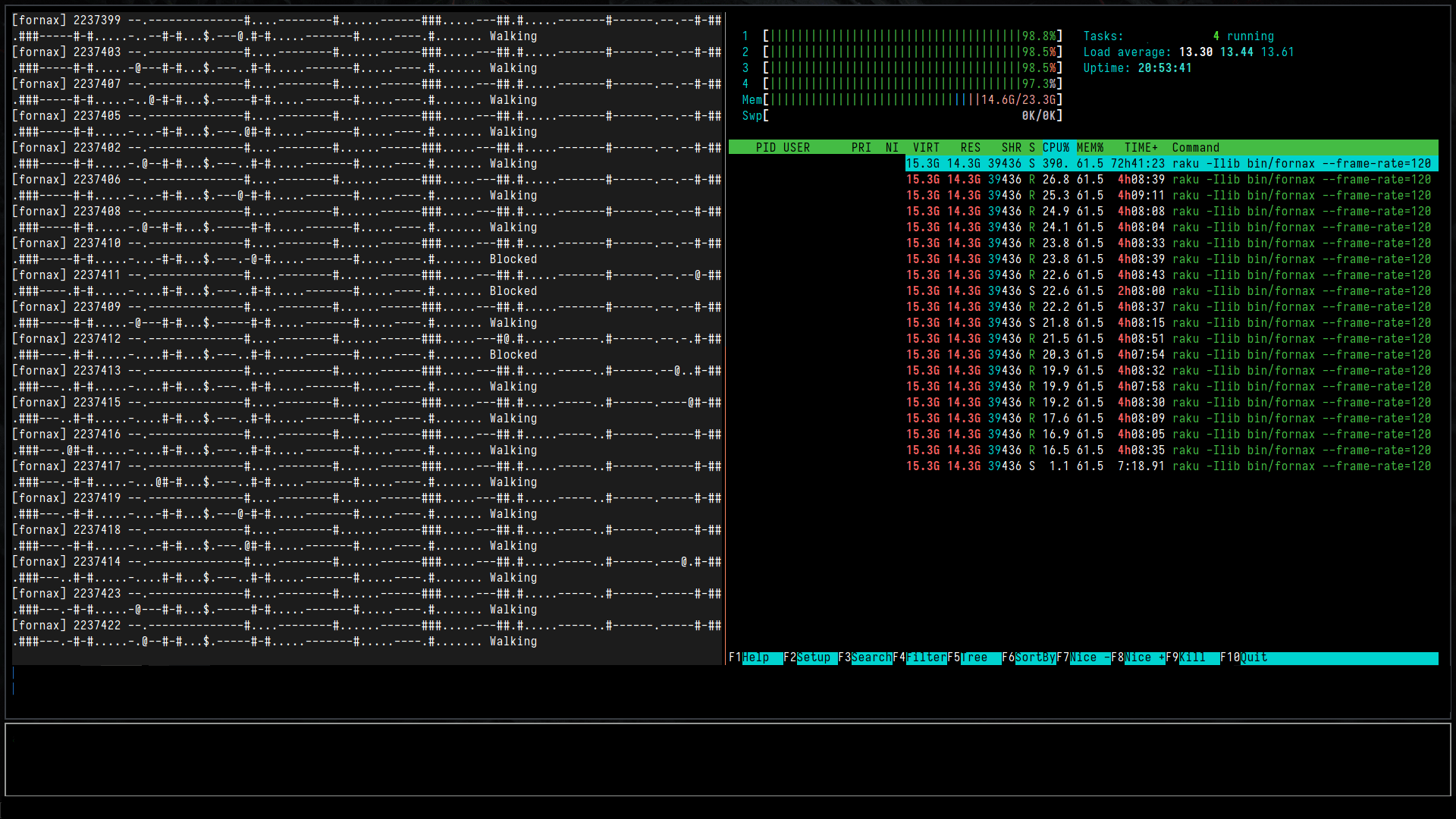
After the initial read, memory usage kept increasing with the iteration count. I don't see anything in the loop that might be causing this. I'll investigate this later someday.
These images are still there on the machine, they're taking 56GB (449M
compressed with ~xz -9). The program ran for ~1d 20h. I don't know why
the memory usage would go that high, it started with ~700M (which is the
size of input file) – I believe this should've been lazy so it
shouldn't have read it all at once.
I'll probably end up deleting the images, there is no use for them. Combining it at 1fps would take a few days but then the projected size is huge (4GB) according to my calculations.
Running this command:
ffmpeg -r 1 -i %08d.png -vf 'tpad=stop_mode=clone:stop_duration=4' -vcodec libx264 -crf 28 -pix_fmt yuv420p /tmp/solution.mp4
I let it run for a while and then noted down the encoding speed, here is a little table:
| filter | encoding speed |
|---|---|
| default: 1920x1080 | 20x |
scale=960:540 |
32x |
scale=640:360 |
33x |
scale=512:288 |
38x |
scale=384:216 |
36x |
scale=256:144 |
40x |
I linked a few videos I generated in the Demo section.
Also, this led to this issue being filed for PeerTube: https://github.com/Chocobozzz/PeerTube/issues/4516.
Demo
- DFS-33 (2021-11-03): https://andinus.unfla.me/resources/projects/fornax/2021-11-03-DFS-33.mp4
- DFS-51-incomplete (upto 187,628 frames; 120 fps): https://diode.zone/w/4RSFatXPL3GrkUucnFdxVS
- DFS-51-incomplete (upto 4,000 frames; 120 fps): https://diode.zone/w/hWWaw8uKHCP5weUP5WWArD
Improvements
Instead of generating png we could save it as svg and then scale it to
required resolution when combining to make a video. Or maybe we could
run a webserver with Cro and stream those svg files. I think this would
take less storage and I can also generate them on the fly.
Current version does work for when the solution ends in less number of iterations.
2021-11-16
From https://github.com/andinus/fornax/commit/7858dba48b41417f951031d36e7fbf66da8d14e2:
Earlier we marked paths as unvisited right after we backtrack out of it. This is not really necessary for us to get the solution because if we're not able to find a path through that block then we won't find it with another way of reaching that block either.
Explanation: AB. X..
If we can't find a path to destination from AX… then we won't find it from ABX… either. Earlier we were trying ABX… too. I had this idea in mind because before this I wrote a word search program that walked in DFS manner, in that case this was required because ABX… could form a word that AX… couldn't.
It shouldn't really take 4.8 million+ iterations to get a solution to the discussed maze. After this fix it will finish it quickly even if it's very unlucky and has to cover the whole maze/bump into every block.
